搜索引擎基础
什么是搜索引擎
搜索引擎是可搜索的网络内容数据库,由两个核心部分组成:搜索索引(存储网页信息的数字图书馆)和搜索算法(从索引中匹配结果的计算机程序)。当用户输入搜索查询时,搜索引擎通过算法在索引中查找最相关的结果,并按相关性排序呈现给用户。
搜索引擎的工作原理可以简单概括为:发现网页、抓取内容、建立索引、理解查询、匹配结果、排序呈现。这个过程涉及复杂的技术系统,包括网络爬虫、索引器、检索器、排名算法等多个模块协同工作。
搜索引擎的目标
每个搜索引擎的目标都是为用户提供最相关、最有用的搜索结果。搜索引擎通过不断提升搜索结果质量来获得市场份额,用户满意度直接影响搜索引擎的竞争力和商业价值。Google之所以占据全球91%的市场份额,很大程度上是因为其搜索结果的质量和相关性优于竞争对手。
搜索引擎如何赚钱
搜索引擎主要有两种搜索结果:自然搜索结果(来自搜索索引,无法付费获得)和付费搜索结果(来自广告商,可以付费投放)。每次用户点击付费搜索结果时,广告商需要向搜索引擎支付费用,这就是按点击付费(PPC)广告模式。市场份额越大,用户越多,广告点击越多,搜索引擎的收入就越高。
Google的广告收入占其总收入的80%以上,Bing也为微软贡献了可观的广告收入。这种商业模式使得搜索引擎有动力不断提升搜索结果质量,吸引更多用户,从而获得更多广告收入。
搜索引擎如何构建索引
搜索引擎构建索引的过程包括四个主要步骤:发现URLs、爬取网页、处理和渲染内容、建立索引。以下是Google使用的简化流程:
URLs:网页发现
一切从已知的URL列表开始。Google通过多种方式发现新网页:从外链发现(如果已知页面链接到新页面,Google可以从那里找到它)、从sitemap发现(网站所有者通过sitemap告诉Google哪些页面重要)、从URL提交发现(网站所有者可以在Google Search Console中请求抓取特定URL)。
Google拥有数百亿网页的索引,当有人从已知页面链接到新页面时,Google的爬虫可以跟随链接发现新内容。sitemap是网站所有者主动告诉搜索引擎网站结构的重要方式,可以加快新页面的发现和索引速度。
爬虫:网页抓取
网络爬虫(也称为蜘蛛或机器人)是自动化的程序,负责在互联网上发现和抓取网页内容。Google的爬虫叫做Googlebot,Bing的爬虫叫做Bingbot。爬虫通过跟踪网页中的超链接,持续发现新页面并抓取内容。
爬虫工作原理:爬虫从种子URL(Seed URLs)开始,访问初始网页列表,分析页面内容并提取所有超链接,将新发现的链接加入待访问队列。爬虫遵循网站所有者设定的规则,主要通过robots.txt文件了解哪些页面可以抓取、哪些应该忽略。爬虫采用宽度优先(BFS)或深度优先(DFS)等策略来平衡抓取效率和覆盖范围。现代爬虫系统需要考虑爬取频率控制、URL去重、动态内容渲染、爬取优先级等技术问题。
随着AI平台的兴起,除了传统的搜索引擎爬虫(如Googlebot、Bingbot),还出现了AI爬虫(如GPTBot、ClaudeBot),它们用于训练大语言模型或实时检索网页内容。搜索引擎爬虫和AI爬虫在工作方式、技术能力和访问目的上存在显著差异。如果您想深入了解网络爬虫的工作原理、搜索引擎爬虫与AI爬虫的区别,以及如何管理和优化爬虫访问,可以查看我们的网络爬虫完整指南。
处理和渲染
处理是Google理解和提取关键信息的过程。为了做到这一点,Google需要渲染页面,即运行页面的代码来理解用户看到的内容。这个过程涉及提取链接和存储内容以供索引。
Google需要处理各种类型的网页内容,包括HTML、CSS、JavaScript、图片、视频等。对于JavaScript渲染的页面,Google需要执行JavaScript代码才能看到完整内容。这个过程需要大量的计算资源,Google使用分布式系统来处理数万亿个网页。
索引:建立搜索库
索引器负责将爬虫抓取的原始网页内容解析为结构化数据,提取关键词、元数据及内容特征,并建立倒排索引(Inverted Index)等数据库结构,以实现快速检索。
索引过程:索引器首先解析HTML文档,提取标题、正文、链接、图片alt文本、元数据(meta tags)等元素。然后对文本内容进行分词、去停用词、词干提取等自然语言处理操作。最后建立倒排索引,将每个关键词映射到包含该关键词的所有网页列表,这样当用户搜索某个关键词时,搜索引擎可以快速找到相关页面。
搜索索引是用户使用搜索引擎时搜索的内容库。AI助手如ChatGPT、Claude、Gemini也使用搜索索引来查找网页。这就是为什么在Google、Bing等主要搜索引擎中被索引如此重要。除非您在索引中,否则用户无法找到您。
现代搜索引擎的索引系统非常庞大,Google的索引系统Alexandria负责存储和管理数万亿个网页的索引数据。索引系统还需要处理索引更新(新页面、页面更新、页面删除)、索引压缩(减少存储空间)、分布式存储(跨多个数据中心)等技术挑战。索引的质量直接影响搜索结果的准确性和相关性。
搜索引擎如何排名页面
发现、爬取和索引内容只是第一步。搜索引擎还需要一种方法来对匹配的结果进行排名,当用户执行搜索时返回最相关的结果。这是搜索算法的工作。
什么是搜索算法
搜索算法是从索引中匹配和排名相关结果的公式。Google在其算法中使用许多因素,这些因素共同决定哪些页面应该出现在搜索结果的前列。
关键排名因素
没有人知道Google的所有排名因素,因为Google没有完全披露它们。但我们确实知道一些关键因素。让我们看看其中几个:
外链(Backlinks)
外链是从一个网站上的页面链接到另一个网站的链接。它们是Google最强的排名因素之一。这就是为什么我们在对超过10亿页面的研究中看到链接域名和自然流量之间存在强相关性的原因。
不仅仅是数量,质量也很重要。拥有几个高质量外链的页面通常比拥有许多低质量外链的页面排名更高。高质量的外链来自权威网站、相关主题网站、自然获得的链接(而非购买或交换的链接)。
相关性(Relevance)
相关性是给定结果对搜索者的有用性。Google有多种方法来确定这一点。在最基本的层面上,它查找包含与搜索查询相同关键词的页面。它还查看交互数据,看看其他人是否发现结果有用。
相关性不仅包括关键词匹配,还包括语义相关性、主题相关性、用户意图匹配等。Google使用机器学习模型(如BERT)来更好地理解查询意图和内容语义,提升搜索结果的相关性。
新鲜度(Freshness)
新鲜度是一个依赖于查询的排名因素。对于需要新鲜结果的搜索,它的作用更强。这就是为什么您看到“最新Netflix剧集“的搜索结果顶部是最近发布的内容,而"如何解魔方"的搜索结果则不是。
对于新闻、事件、产品发布等时效性强的查询,新鲜度是重要的排名因素。但对于"如何"类查询、定义类查询等,内容质量和权威性比新鲜度更重要。
页面速度(Page Speed)
页面速度是桌面和移动设备上的排名因素。但它更像是一个负面排名因素,而不是正面因素。这是因为它对最慢的页面产生负面影响,而不是对闪电般快速的页面产生正面影响。
页面速度影响用户体验,加载缓慢的页面会导致用户跳出率增加、停留时间减少。Google使用Core Web Vitals指标(LCP、FID、CLS)来衡量页面性能,这些指标直接影响搜索排名。
移动友好性(Mobile-Friendliness)
自2019年Google转向移动优先索引以来,移动友好性一直是移动和桌面上的排名因素。这意味着Google主要使用页面的移动版本进行索引和排名。
移动友好性包括响应式设计、触摸友好的界面、快速加载速度、可读的字体大小等因素。不符合移动友好性标准的页面在移动搜索结果中的排名会受到影响。
搜索引擎如何个性化结果
Google为每个用户定制搜索结果。它使用位置、语言、搜索历史等信息来实现这一点。让我们更仔细地看看这些因素:
位置(Location)
Google使用您的位置来个性化具有本地意图的搜索结果。这就是为什么"意大利餐厅"的所有结果都来自或关于本地餐厅的原因。Google知道您不太可能为了午餐而飞越半个世界。
对于本地搜索查询,Google会优先显示附近的商家和服务。位置信息来自用户的IP地址、GPS数据(移动设备)、Google账户设置等。
语言(Language)
Google知道向西班牙用户显示英文结果没有意义。这就是为什么它向使用不同语言的用户排名内容的本地化版本(如果可用)。
Google会根据用户的浏览器语言设置、Google账户语言偏好、搜索查询语言等因素来确定应该显示哪种语言的结果。对于多语言网站,Google会尝试显示与用户语言匹配的版本。
搜索历史(Search History)
Google保存您做的事情和去的地方,以提供更个性化的搜索体验。您可以退出此功能,但大多数人可能不会。
搜索历史影响搜索结果的个性化,Google会根据用户过去的搜索行为、点击的链接、访问的网站等信息来调整搜索结果。这使得每个用户的搜索结果都是独特的。
技术SEO考虑因素
理解搜索引擎的工作原理有助于优化网站的技术架构,提升搜索引擎的抓取和索引效率。技术SEO涉及多个方面,包括网站结构优化、页面性能优化、移动友好性、结构化数据等。
通过优化robots.txt文件,网站所有者可以控制哪些页面允许爬虫抓取。通过提交sitemap,可以加快新页面的发现速度。通过优化页面加载速度、移动友好性、结构化数据等技术因素,可以提升搜索排名和用户体验。
如果您想深入了解技术SEO的具体实践方法和优化技巧,可以参考我们的SEO学习资源页面,其中包含了系统性的SEO学习指南和最佳实践。同时,您也可以查阅我们的SEO词汇表,了解robots.txt、sitemap、结构化数据、Core Web Vitals等技术SEO术语的详细定义和解释。
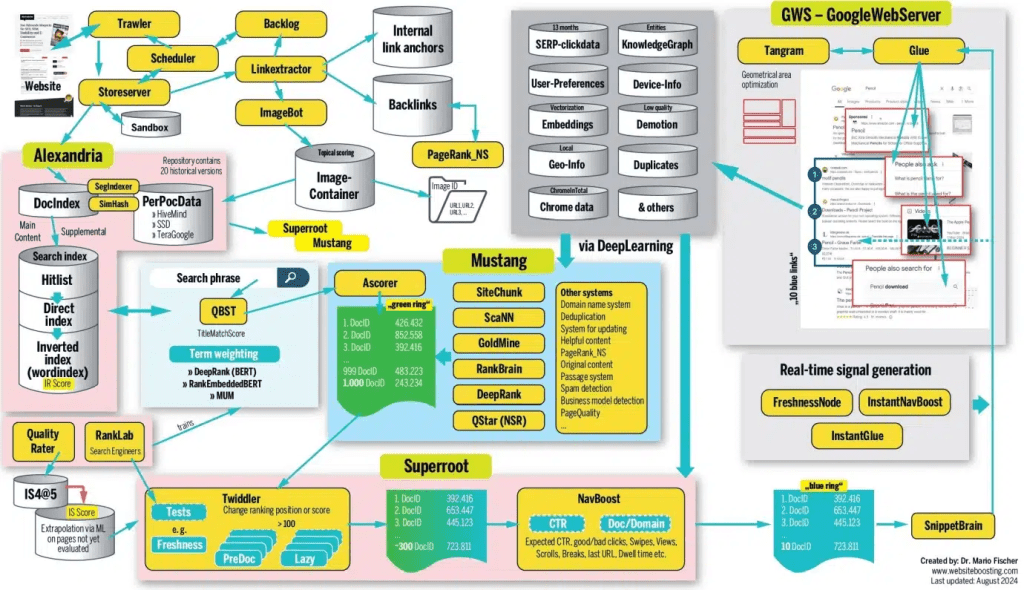
通过谷歌泄露的官方文档可以看出排名算法是如何运作的:谷歌排名算法很复杂,甚至参与算法的员工也无法解释每个因素的权重和如何共同作用;整个系统由众多更小的系统组成,例如抓取系统Trawler、索引系统Alexandria、排名系统Mustang、查询处理系统SuperRoot
检查网站是否出现在搜索引擎当中
使用插件
使用浏览器插件是检查网站在搜索引擎中索引情况的最便捷方法。这些插件可以快速显示网站在不同搜索引擎中的索引状态,包括Google、Bing、百度等主流搜索引擎。插件通常会在浏览器工具栏显示索引数量,点击即可查看详细信息。
主流的可以看,Sogou不准,我都没有那么多页面
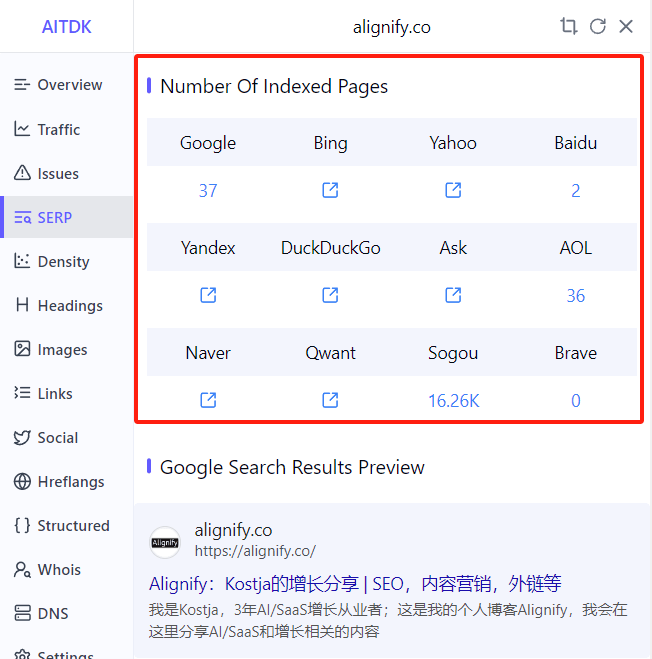
在对应搜索引擎中搜索
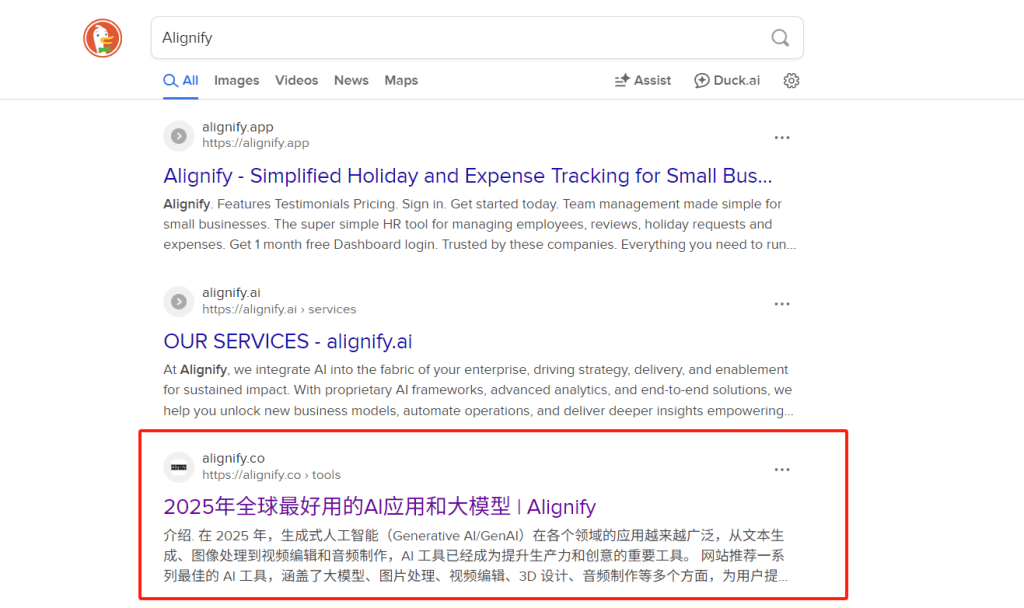
直接在搜索引擎中搜索网站的品牌词或域名,是验证网站是否被索引的最直接方法。除了搜索品牌词,还可以使用site:yourdomain.com搜索指令来查看所有被索引的页面。这个指令可以显示搜索引擎索引了网站的哪些页面,以及索引的数量。
需要注意的是,site:搜索指令并不是所有搜索引擎都支持。主流搜索引擎如Google、Bing、百度等都支持此指令,但一些较小的或特殊的搜索引擎可能不支持。
算法还是不太ok,搜品牌词出来的不是首页