文章简介
本文将全面介绍AI模型测评平台的核心概念、使用价值和发展趋势。我们将探讨什么是AI模型测评平台、这些平台如何帮助开发者进行科学评估,以及2026年最值得关注的6款专业工具。从模型对比到性能监控,从开发测试到生产部署,这些平台为AI应用的整个生命周期提供全面支持,帮助企业和开发者做出明智的技术决策,提升AI应用的质量和效率。
什么是AI模型测评平台
AI模型测评平台是帮助开发者、研究者和企业系统性地测试、评估和对比不同AI模型性能的专业工具。这些平台通过标准化的评估指标、基准测试和对比分析,帮助用户判断模型是否达到预期目标,是否能够高效稳定地运行,以及是否适用于真实世界的实际应用需求。
AI模型测评平台的核心价值在于提供客观、可量化的模型性能评估,帮助用户做出明智的模型选择决策。无论是评估大语言模型的准确性、图像生成模型的质量,还是对比不同API提供商的响应速度和成本效益,这些平台都能提供全面的评估数据和深入的分析洞察。通过系统性的测评,用户可以避免选择不适合的模型,优化AI应用的性能和成本。
AI模型测评工具如何工作
AI模型测评技术主要围绕评估指标设计、基准测试构建、性能对比分析和结果可视化四个核心环节展开。评估指标方面,平台需要设计涵盖准确性、速度、成本、安全性等多个维度的指标体系,针对不同AI任务(如NLP、计算机视觉、多模态等)采用相应的评估方法。基准测试则涉及构建标准化的测试数据集、设计测试场景和定义评估标准,确保评估结果的客观性和可重复性。
性能对比分析需要收集大量模型的运行数据,通过自动化测试流程和实时监控机制,持续跟踪模型性能变化。结果可视化则通过排行榜、对比图表、详细报告等形式,帮助用户直观理解模型性能差异。随着AI技术的快速发展,测评平台也在集成更先进的评估方法,如使用LLM作为评判者(LLM-as-a-Judge)、多维度评估框架、实时性能监控等,为AI应用开发提供更全面的评估支持。
2026年最好的AI模型测评平台
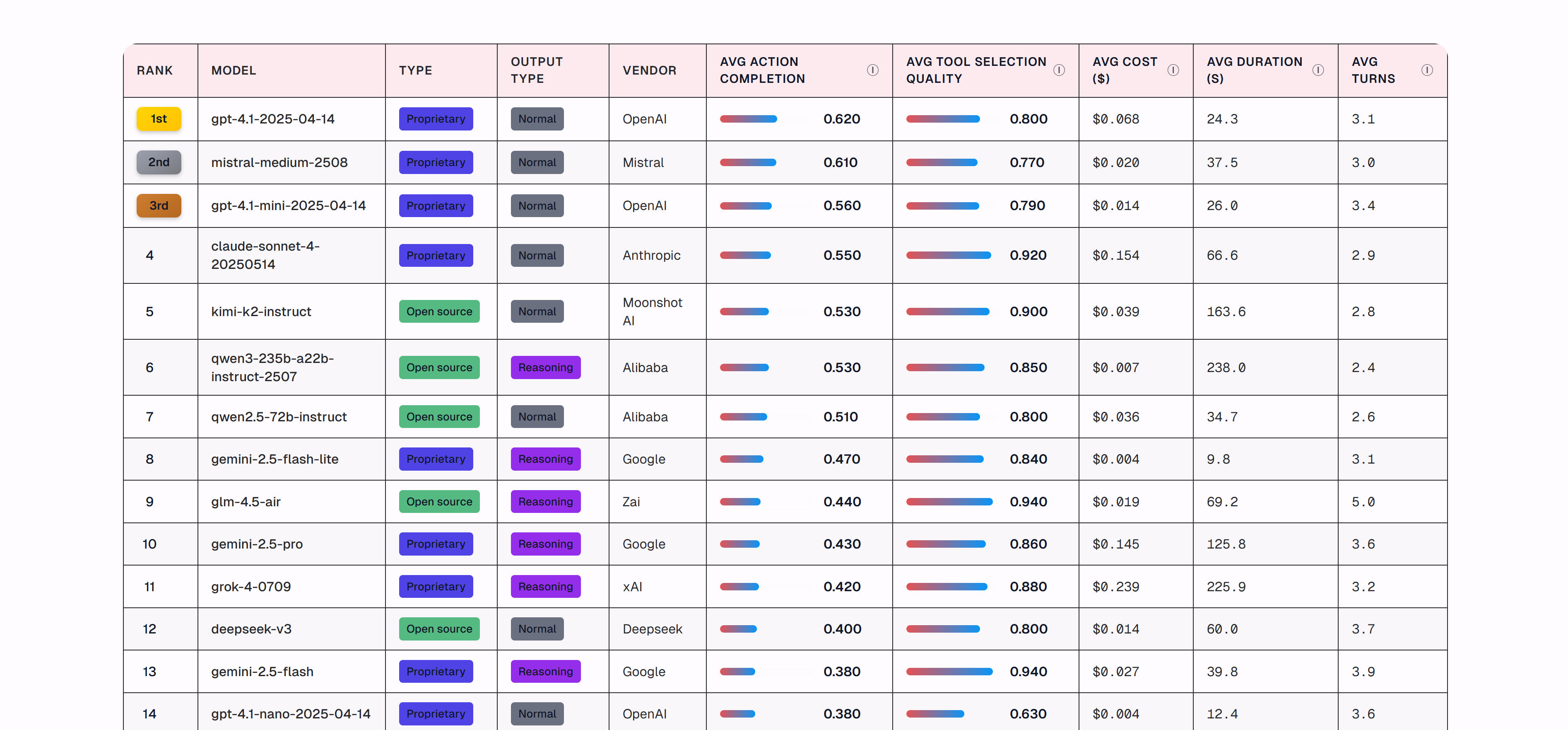
1. Artificial Analysis:AI模型和API提供商分析
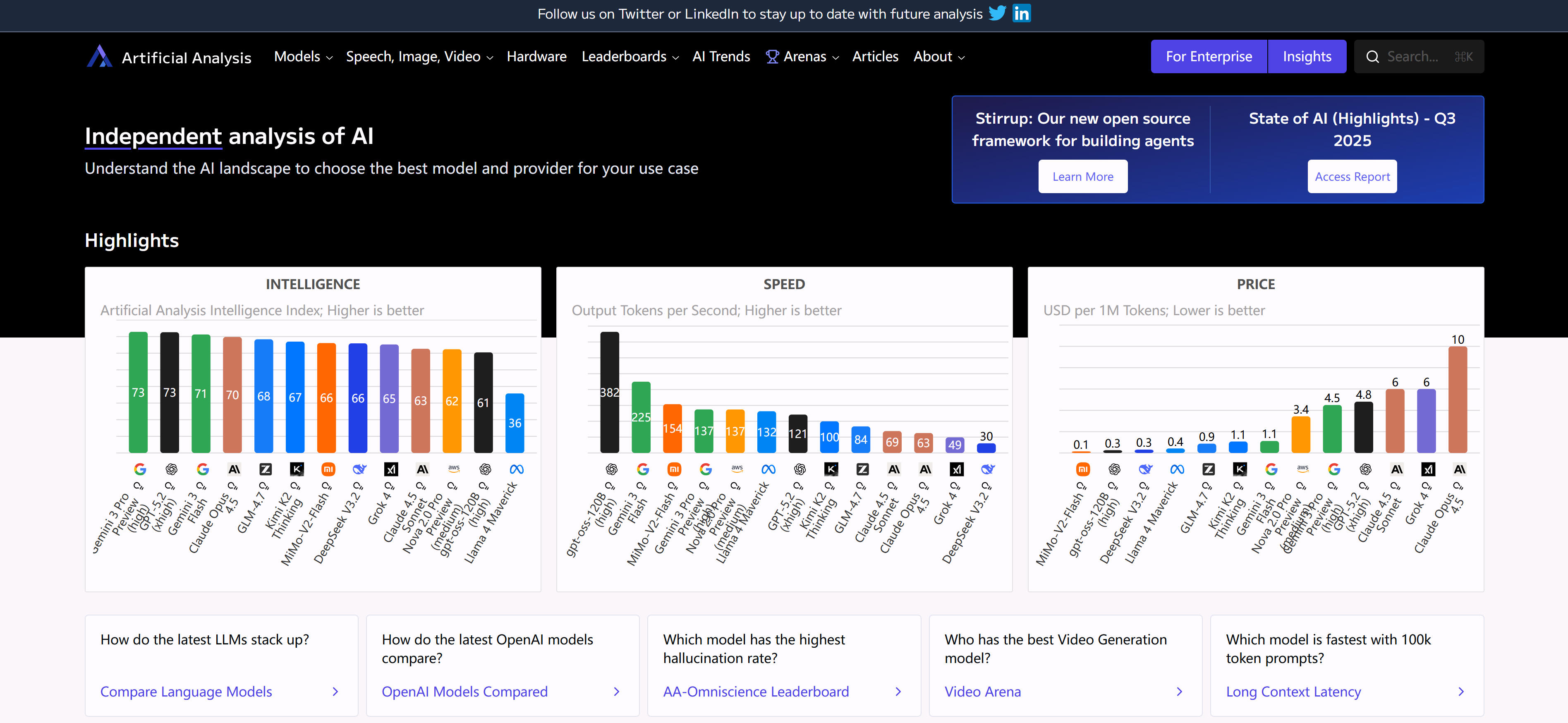
Artificial Analysis是一个专业的AI模型和API提供商分析平台,专注于评估和对比不同AI服务提供商的模型性能、响应速度、成本效益和可靠性。平台通过系统性的基准测试和实时监控,为用户提供全面的API提供商对比数据,帮助用户选择最适合的AI服务。平台特点包括全面的API提供商覆盖、详细的性能指标分析、成本效益对比和可靠性评估,提供直观的对比图表和详细的分析报告,帮助用户快速了解不同提供商的优势和劣势。对于需要选择AI API服务的开发者和企业,Artificial Analysis提供了重要的决策支持工具。
2. LMArena:AI模型对比评估平台
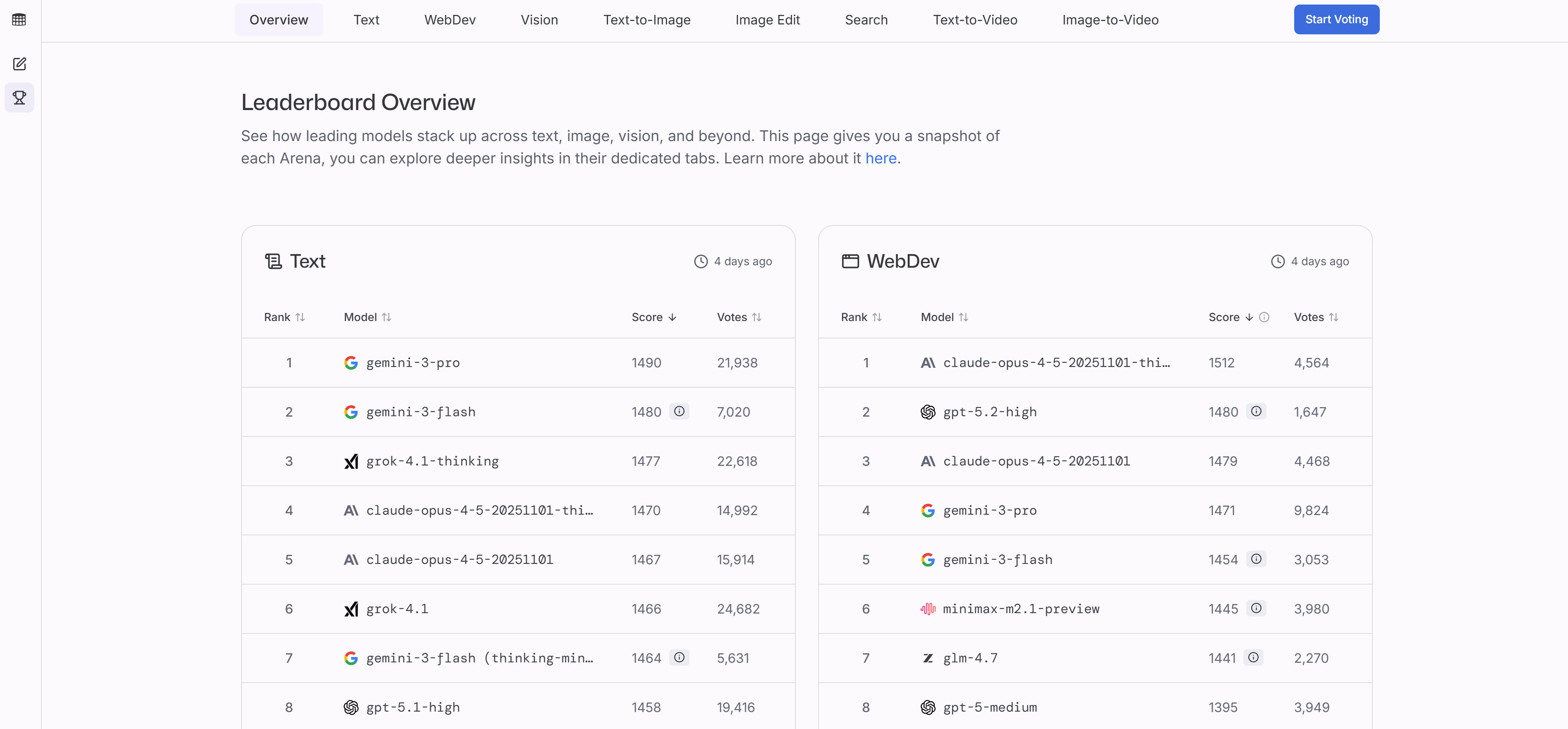
LMArena是一个创新的AI模型对比评估平台,帮助用户并排对比和评估不同AI模型的性能、准确性、速度和适用性。平台专注于分析模型的表现而非创建AI,通过系统性的测试和对比,帮助用户找到最适合特定任务的AI模型。平台特点包括直观的模型对比界面、多维度性能评估、实时测试功能和社区反馈机制,支持用户输入自己的测试用例,对比不同模型的响应质量和性能表现。通过公开的排行榜和社区反馈,用户可以了解模型的最新表现和用户评价。对于需要选择AI模型的开发者和企业,LMArena提供了便捷的对比评估工具。
3. Scale SEAL:专家驱动的LLM排行榜
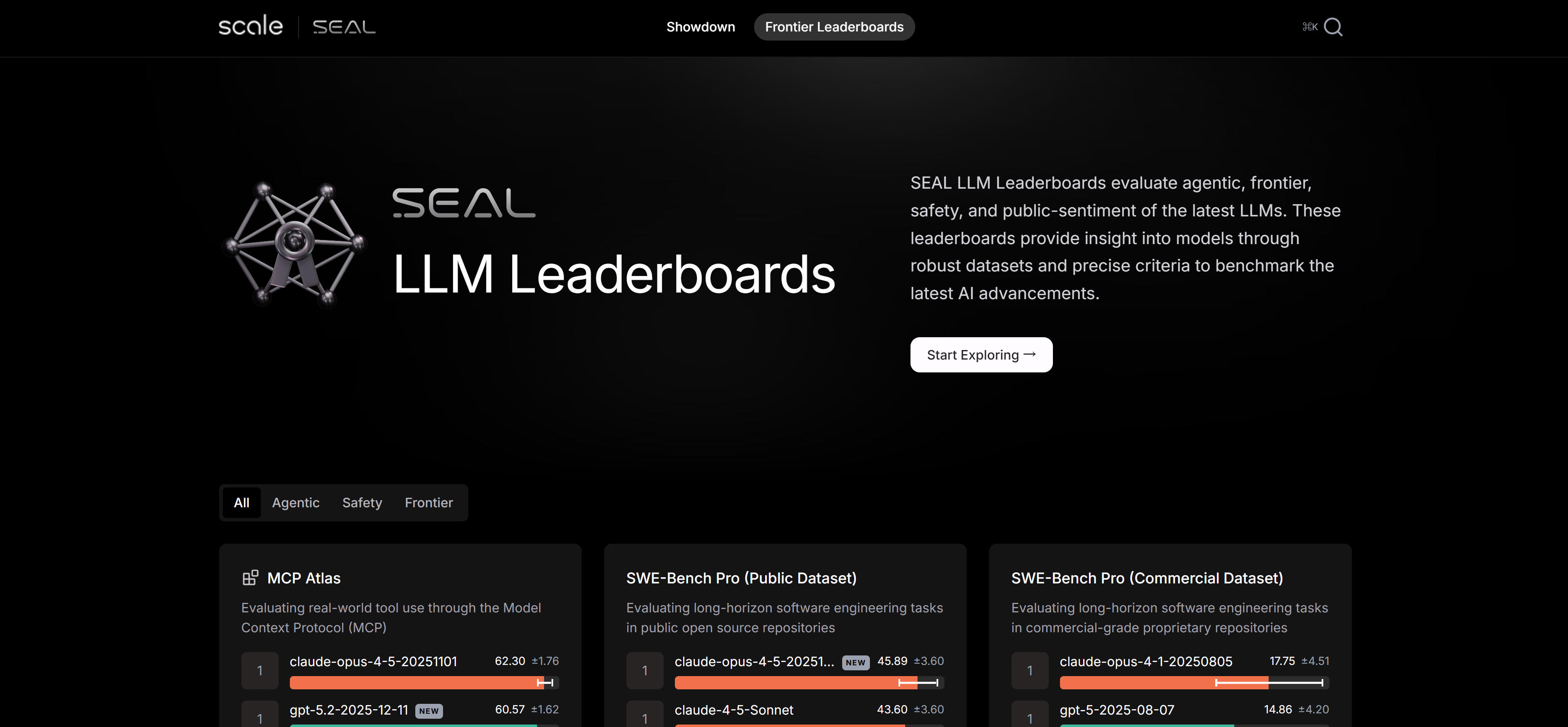
Scale SEAL(Systematic Evaluation of AI Language Models)是Scale公司推出的专家驱动的LLM评估排行榜,采用严格的评估标准和专业的评估方法,对大型语言模型进行系统性的性能评估。平台专注于前沿AI能力的评估,为研究者和开发者提供权威的模型性能排名。平台特点包括专家驱动的评估方法、严格的评估标准、全面的能力测试和持续更新的排行榜,通过多维度测试评估模型在不同任务上的表现,包括推理能力、知识理解、代码生成等。评估结果经过专业审核,确保客观性和准确性。对于关注前沿AI模型性能的研究者和开发者,Scale SEAL提供了权威的评估参考。
4. OpenRouter Rankings:LLM使用排行榜
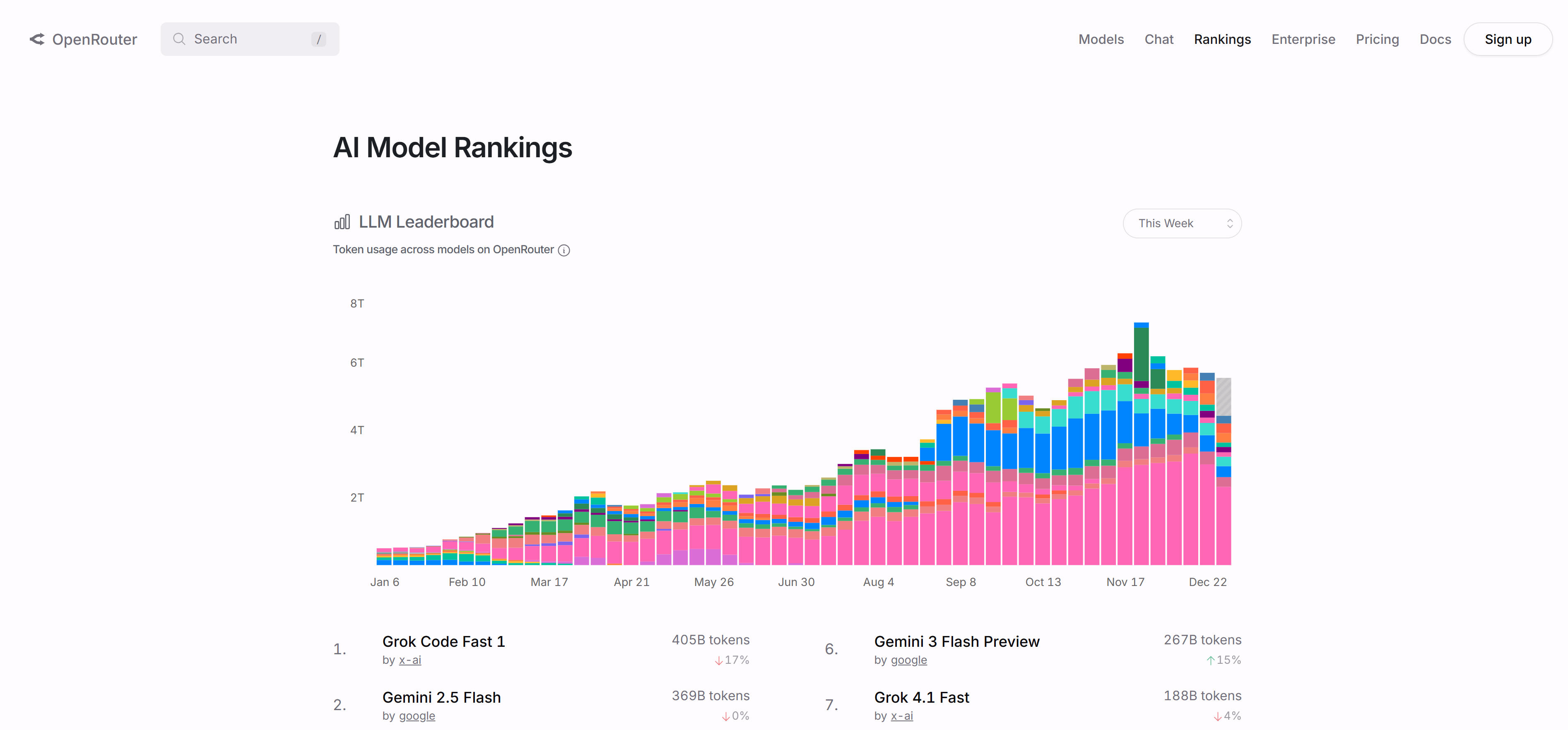
OpenRouter Rankings是基于实际使用数据的LLM排行榜,通过追踪OpenRouter平台上各模型的真实使用情况,提供基于市场选择的模型排名。平台展示不同模型在代码生成、对话、多语言等场景下的实际使用份额和性能表现。平台特点包括基于真实使用数据的排名、多维度使用场景分析、市场占有率统计和实时数据更新,提供按用例、语言、编程语言、上下文长度等多个维度的模型对比,帮助用户了解模型在实际应用中的表现。对于需要了解模型市场接受度的开发者和企业,OpenRouter Rankings提供了独特的市场视角。
5. Galileo AI:AI可观测性和评估平台
Galileo AI是一个专业的AI可观测性和评估工程平台,专注于AI系统的离线评估和生产环境监控。平台提供从评估到防护栏(guardrail)的完整生命周期管理,帮助开发者构建可靠、安全的AI应用。平台特点包括全面的评估指标库、自动调优的评估方法、从评估到防护栏的转换、实时监控和告警功能,支持RAG评估、智能体评估、安全性评估等多种评估类型,并提供Luna模型将昂贵的LLM评估转换为低成本、低延迟的监控模型。对于需要构建生产级AI应用的企业,Galileo AI提供了完整的评估和监控解决方案。
6. Evidently AI:AI评估和LLM可观测性平台
Evidently AI是一个开源的AI评估和LLM可观测性平台,提供100多种内置评估指标,支持LLM测试、RAG评估、对抗测试、AI智能体测试等多种评估场景。平台基于开源的Evidently Python库构建,提供透明、可扩展的评估工具。平台特点包括丰富的评估指标库、开源透明、易于扩展、支持自定义评估和持续测试,提供自动化评估、合成数据生成、持续测试监控等功能,帮助开发者及时发现模型问题、数据漂移和性能回归。平台支持RAG评估、对抗测试、智能体工作流验证等多种用例,为AI应用开发提供全面的质量保障。对于需要开源评估工具的开发者,Evidently AI提供了强大的评估和监控能力。
AI模型测评工具对比:选择最适合你的
通过以下对比表格,可以快速了解各平台的核心优势和适用场景,帮助你选择最适合的AI模型测评工具。
1. 模型选择和对比
AI模型测评工具在模型选择阶段发挥关键作用,帮助用户系统性地对比不同模型的性能表现。使用LMArena和Artificial Analysis等平台,用户可以并排对比多个AI模型的准确性、响应速度和可靠性指标,通过直观的界面快速了解各模型的优势和劣势。同时,Scale SEAL和OpenRouter Rankings提供权威的排行榜和市场数据,帮助用户从专业评估和实际使用两个维度评估模型质量,为最终的模型选择提供科学依据。
2. 模型开发和优化
在AI模型开发过程中,测评工具提供持续的评估和反馈,帮助开发者优化模型性能。Galileo AI和Evidently AI等平台支持自动化评估流程,可以在开发的不同阶段对模型进行全面测试,识别潜在的性能问题和改进方向。通过持续监控和迭代评估,开发者能够及时发现数据漂移、性能回归等问题,并基于评估数据进行针对性优化,提升模型的准确性和可靠性。
3. 生产环境监控
AI模型测评工具在生产环境中提供实时监控和安全保障,确保AI应用的稳定运行。Galileo AI等企业级平台支持生产环境的持续评估和告警,能够实时检测模型性能变化、数据异常和安全威胁。通过自动化监控和防护栏功能,平台可以自动阻止有害响应和异常行为,保障AI应用的安全性和可靠性。对于企业级AI部署,生产环境监控是确保系统稳定性的重要保障。
4. 研究和学术评估
在AI研究领域,测评工具提供标准化评估方法和权威数据,支持学术研究和论文发表。Scale SEAL等平台采用严格的评估标准和专业方法,为前沿AI模型提供客观的性能评估,帮助研究者了解最新技术进展。通过标准化评估流程和公开数据,研究人员可以进行可重复的对比分析,为AI技术的学术研究和产业发展提供可靠依据,推动整个AI领域的发展。
如何选择AI模型测评平台
根据您的评估目的、评估指标和功能需求、技术集成能力、成本预算和数据安全要求,选择合适的AI模型测评平台可以显著提升模型评估效率和质量。
1. 明确使用需求
明确评估目的:确定你的主要需求是模型对比、性能评估、生产监控还是研究分析。如果主要需要对比不同模型,LMArena和Artificial Analysis更适合;如果需要生产环境监控,Galileo AI和Evidently AI更合适;如果关注权威评估,Scale SEAL是首选。
2. 评估评估指标和功能需求
检查平台是否提供你需要的评估指标和功能。不同平台支持的评估类型、指标范围、测试能力可能不同,需要根据具体需求选择。例如,Galileo AI和Evidently AI提供更全面的评估指标库,而LMArena和Artificial Analysis更专注于模型对比。根据评估需求选择提供相应指标和功能的平台。
3. 评估技术集成能力
评估平台的技术集成能力和API支持。对于需要集成到现有系统的企业,选择提供API和SDK的平台更合适。Galileo AI和Evidently AI提供更完善的集成能力,而对比平台主要提供Web界面。根据集成需求选择提供相应API和SDK的平台,确保能够无缝集成到工作流。
4. 考虑成本预算和定价模式
考虑平台的使用成本和定价模式。开源平台(如Evidently AI)通常免费,但需要自己部署和维护;SaaS平台(如Galileo AI)提供托管服务,但需要付费;对比平台通常免费使用,但功能可能有限。根据预算和需求选择合适的方案,比较不同平台的性价比。
5. 检查数据安全和合规性
对于企业用户,需要检查平台的数据安全措施和合规性认证。确保平台能够满足数据保护要求,支持私有部署或符合企业安全标准。Galileo AI和Evidently AI提供企业级的安全和合规支持。根据数据安全要求选择合适的平台,确保敏感数据得到充分保护。
结论
AI模型测评平台为AI应用开发提供了重要的评估和决策支持工具,从模型选择到性能优化,从开发测试到生产监控,为不同需求的用户提供了丰富的选择。对比平台(如LMArena、Artificial Analysis)帮助用户快速对比和选择模型;权威评估平台(如Scale SEAL)提供专业的模型性能排名;使用数据平台(如OpenRouter Rankings)展示模型的实际应用表现;评估工程平台(如Galileo AI、Evidently AI)提供全面的评估和监控能力。
选择合适的AI模型测评平台需要根据具体需求、使用场景和技术能力进行综合考虑。对于需要快速对比模型的用户,LMArena和Artificial Analysis提供了便捷的对比工具;对于需要生产环境监控的企业,Galileo AI和Evidently AI提供了完整的评估和监控解决方案;对于关注权威评估的研究者,Scale SEAL提供了专业的评估参考。无论你的需求是什么,都能在这些平台中找到合适的评估工具和支持。