What Are AI Knowledge Base Tools
AI knowledge base tools are intelligent systems that automatically collect, organize, connect, and retrieve information using artificial intelligence. These platforms typically feature smart search, automatic summarization, knowledge graph construction, and content generation capabilities, helping users transform scattered information into structured, actionable knowledge resources.
From personal note-taking to enterprise-level knowledge management, AI knowledge bases offer a different dimension beyond meeting note tools, focusing more on long-term accumulation and systematic knowledge organization. Meanwhile, they form a complete workflow ecosystem with productivity tools and text generation tools.
How AI Knowledge Base Tools Work
AI knowledge base tools operate on core principles of natural language processing (NLP), machine learning, and knowledge graph technology. First, the system automatically captures and analyzes content in various formats, including documents, web pages, emails, and meeting records. AI algorithms then extract key information, establish relationships, and construct knowledge graphs. Finally, intelligent search and content generation capabilities help users quickly find information or create new content.
These tools typically possess core capabilities including automatic content classification, intelligent tagging, semantic search, content summarization, and knowledge relationship discovery. Through integration with AI search engines, knowledge bases can provide more accurate and contextually relevant search results. Meanwhile, many tools also integrate AI text generation capabilities to automatically generate reports, summaries, or related content based on knowledge base materials.
Best AI Knowledge Base Tools 2026
Here are 11 carefully selected AI knowledge base tools for 2026, covering everything from personal learning to enterprise applications. Each tool has unique advantages to meet different user groups' knowledge management needs.
1. NotebookLM: Smart Document Analysis

NotebookLM is Google's AI-powered document analysis tool that transforms static documents into dynamic, conversational knowledge resources. It features powerful document comprehension capabilities, analyzing content in various formats including PDFs and documents, automatically extracting key information and building knowledge connections. NotebookLM's core differentiator is its audio podcast generation feature, which converts document content into natural conversational audio, allowing users to consume knowledge in an entirely new way.
This tool is particularly suitable for academic researchers, content creators, and professionals. Through its AI-driven Q&A system, users can engage in natural conversations with documents, quickly locating needed information. Meanwhile, the audio podcast functionality makes knowledge acquisition more flexible, allowing users to listen to AI-generated knowledge podcasts during commutes or workouts, significantly improving the efficiency and convenience of knowledge consumption.
2. Notion Knowledge Base: Flexible Collaboration Platform
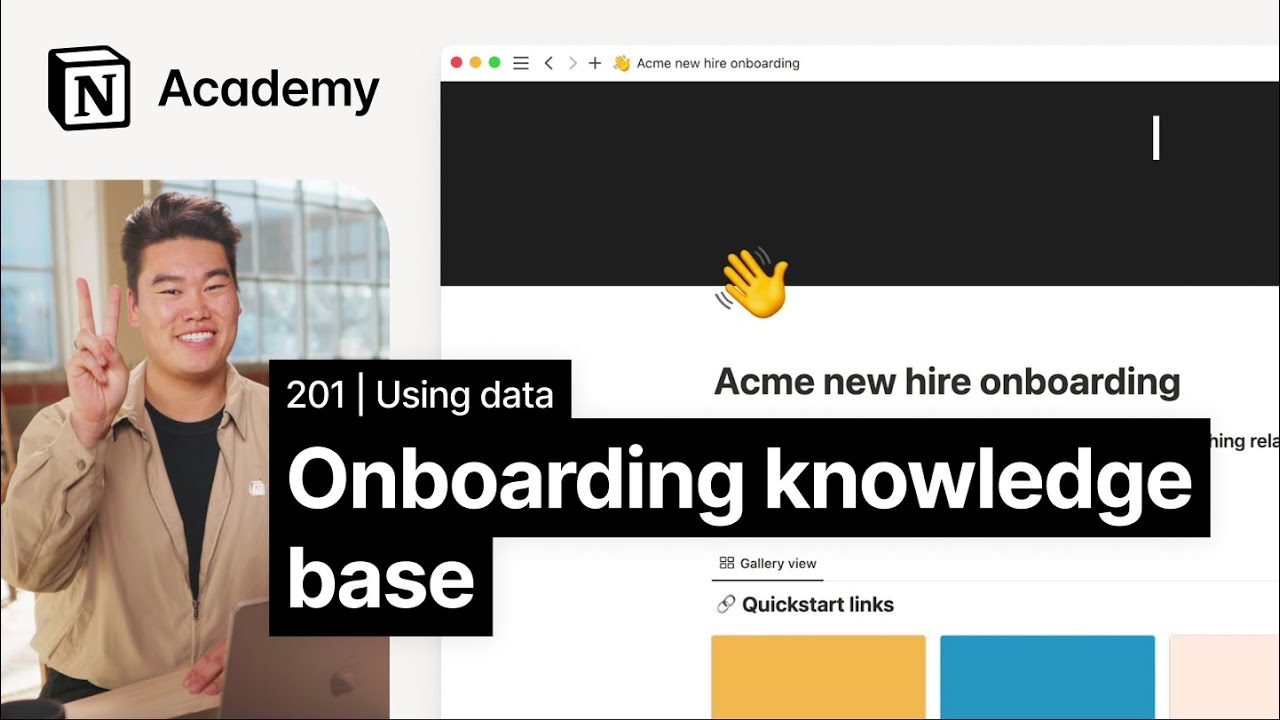
Notion excels as a comprehensive knowledge management platform in the knowledge base domain. It inherits the powerful editing and collaboration capabilities of documents, spreadsheets, and mind maps, allowing users to easily create and manage knowledge content. Notion supports multiple content formats including documents, databases, mind maps, and multimedia, making knowledge creation more effortless. Teams can collaborate on editing in the same platform with real-time synchronization updates, ensuring information timeliness and accuracy.
Notion's knowledge base functionality is particularly suitable for teams and individuals requiring high customization. It provides a rich template library to help users quickly build professional knowledge bases. Meanwhile, powerful search capabilities and tagging systems make knowledge discovery extremely convenient. Whether it's an enterprise-level knowledge management system or personal note organization, Notion can provide flexible and efficient solutions.
3. Slite: Team Knowledge Management
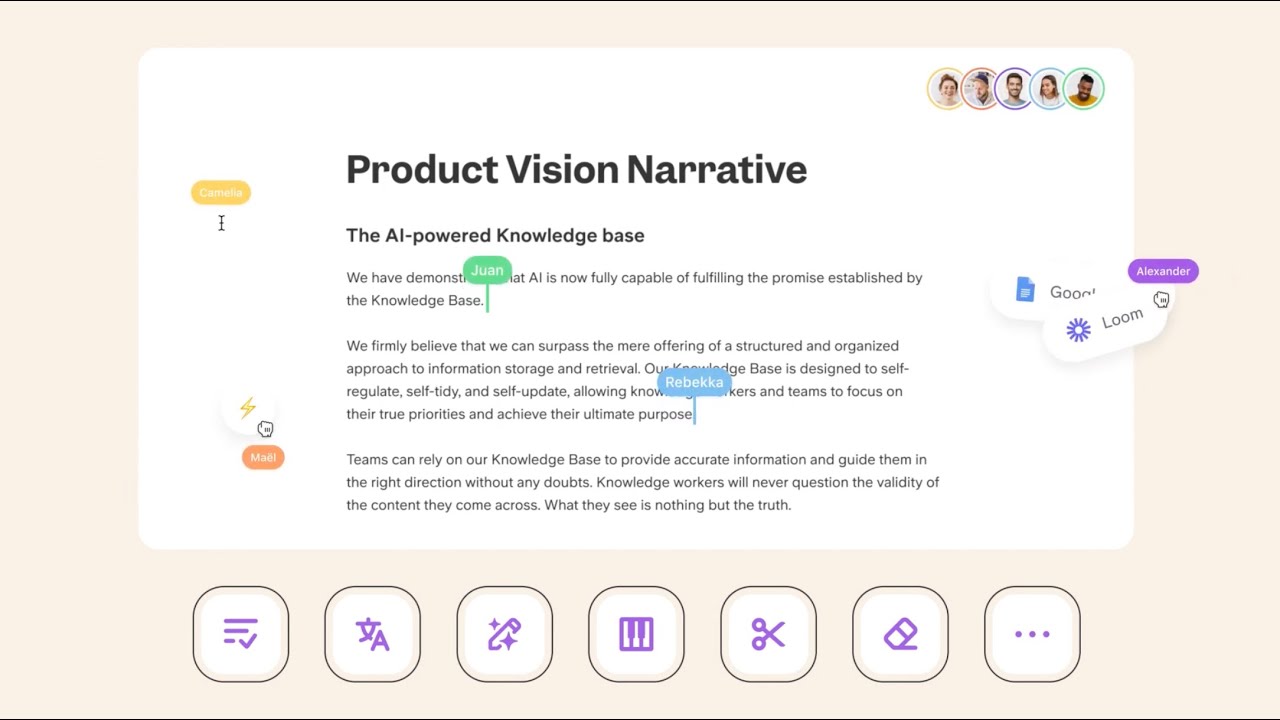
Slite is an AI-driven knowledge management platform designed specifically for teams, committed to breaking down knowledge silos and allowing information to flow freely. It provides a beautiful document editing interface and zero-learning-curve experience, offering AI-enhanced search capabilities from day one. Slite features a built-in document verification system and automated quality maintenance reminders to ensure the accuracy and timeliness of knowledge base content. Through AI-suggested actions, the platform can proactively help maintain knowledge quality.
Slite is particularly suitable for rapidly growing teams and enterprises. It supports flexible permission settings, allowing different access rights to be assigned based on user roles. Meanwhile, powerful search capabilities can quickly locate needed information from massive documents. Whether it's new employee onboarding training or daily knowledge searches, Slite can significantly improve team work efficiency and collaboration quality.
4. Chatbase: AI Customer Service Knowledge Base
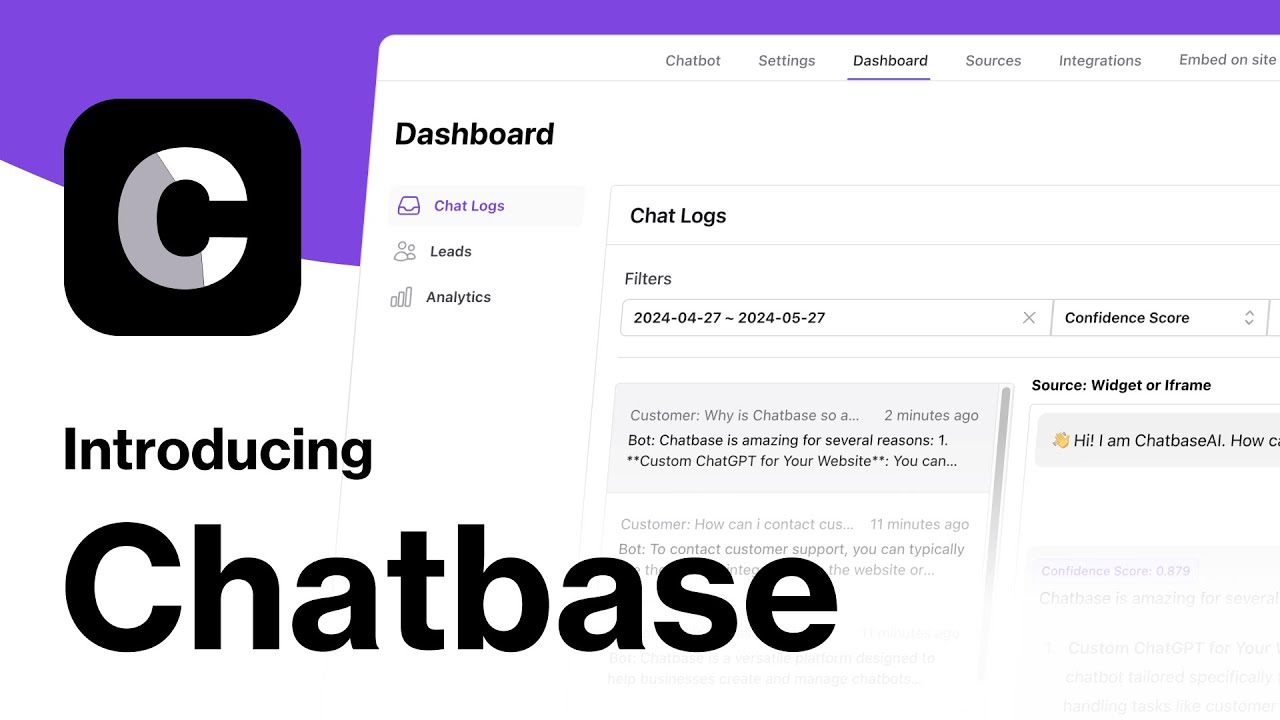
Chatbase is a complete platform purpose-built for LLMs, providing comprehensive AI support agent building solutions. It can train AI agents to handle complex customer queries with reasoning capabilities for effective responses. Chatbase supports multiple model comparisons and configurations to help users find the best setup for their use cases. Meanwhile, smart escalation features ensure agents continuously learn and improve, providing better customer experiences.
This tool is particularly suitable for enterprises needing to handle large volumes of customer inquiries. It supports integration with multiple systems, enabling real-time access to order information, CRM data, and other critical information. Smart escalation can automatically transfer complex issues to human customer service, ensuring all customers receive timely and accurate assistance. Whether it's e-commerce platforms or SaaS providers, Chatbase can significantly improve customer service quality and efficiency.
5. Flowith: Intelligent Workflow Management

Flowith is an agentic workspace that seamlessly integrates AI assistants into workflows. It provides intelligent workflow design and knowledge management capabilities, automatically capturing and organizing information to help users build personalized knowledge systems. Flowith supports integration with multiple data sources including web pages, documents, and multimedia content, analyzing user usage patterns through AI to provide personalized recommendations and insights.
Flowith is suitable for professionals and teams needing to handle complex workflows. It can learn users' thinking patterns and work methods, providing intelligent work suggestions. Through seamless integration with existing tools, Flowith can proactively provide assistance when users need it, greatly improving work efficiency. Whether it's project management, content creation, or knowledge organization, Flowith can serve as a capable AI assistant.
6. Youmind: Learning & Creation Assistant

Youmind is an AI platform that perfectly combines learning and creation, providing users with comprehensive knowledge management and content generation services. It can automatically save and organize content in various formats, including web pages, videos, documents, and notes. By analyzing users' reading and annotation habits, Youmind can provide personalized insights and suggestions to help users deeply understand and master knowledge. Meanwhile, it supports converting research results into various content formats, from reports to presentations, covering all needs.
Youmind is particularly suitable for researchers, educators, and content creators. It provides a project-based workspace that seamlessly connects learning, thinking, and creation. Whether it's academic research, content creation, or personal knowledge management, Youmind can provide powerful AI support to help users transform knowledge into valuable content output.
7. Recall: AI Memory Enhancement

Recall is an AI-driven knowledge memory platform that converts browsing history into structured knowledge bases. It features AI summarization for quick content previews across multiple formats including articles, YouTube videos, podcasts, and PDFs. Meanwhile, Recall integrates spaced repetition algorithms to help users reinforce memory through scientific methods, building long-term knowledge accumulation. The platform supports cross-device synchronization, ensuring users can access their knowledge base anytime, anywhere.
This tool is particularly suitable for learners and professionals who need to process large amounts of information. Through AI-driven chat functionality, users can converse with their knowledge base to quickly find needed answers. Whether it's academic research, skill learning, or professional knowledge accumulation, Recall can help users more effectively manage and memorize information.
8. Remio: Personal AI Assistant

Remio is a personal AI second brain and assistant tool designed specifically for individuals, automatically capturing and organizing users' work content. It runs silently in the background, integrating various information sources including files, meetings, emails, and web pages to build personalized knowledge bases. By analyzing users' past handling methods, Remio can learn personal styles and work logic, providing tailored AI responses. Meanwhile, it supports local data storage to ensure user data privacy and security.
Remio is suitable for knowledge workers who need to handle large amounts of information, including product managers, engineers, salespeople, and students. It can significantly improve work efficiency, helping users quickly find answers in complex information streams. Whether it's project management, customer communication, or learning research, Remio can serve as a reliable AI assistant.
9. Lark Knowledge Base: Enterprise Knowledge Management

Lark Knowledge Base is ByteDance's enterprise-level knowledge management platform, providing comprehensive knowledge organization and management solutions for teams and enterprises. It supports creation in multiple content formats including documents, spreadsheets, and mind maps, greatly facilitating knowledge creation. Lark Knowledge Base features powerful collaboration capabilities, allowing multiple team members to simultaneously edit and manage knowledge, ensuring real-time synchronization and updates. Meanwhile, it provides a refined permission control system where enterprises can set different access rights according to their needs, protecting knowledge security.
Lark Knowledge Base supports importing materials from multiple formats including Confluence, Word, Excel, etc., greatly reducing migration costs. It is particularly suitable for large enterprises and rapidly growing teams, effectively integrating scattered knowledge resources and improving overall team collaboration efficiency. As part of the ByteDance ecosystem, Lark Knowledge Base seamlessly integrates with other office tools, providing enterprises with complete digital office solutions.
AI Knowledge Base Tools Comparison: Choose What's Right for You
Use Cases: 5 Practical Applications
AI knowledge base tools can not only help individuals manage knowledge, but also play important roles in enterprise applications. Here are several typical application scenarios:
Enterprise Knowledge Management
For large enterprises and rapidly growing teams, AI knowledge bases can integrate scattered knowledge resources and break down information silos. Through tools like Slite and Lark, enterprises can build unified knowledge systems to ensure employees can quickly find needed information and improve work efficiency. AI-driven search capabilities can understand employees' query intentions and provide more accurate answers. Meanwhile, fine-grained permission controls ensure knowledge security.
Personal Learning & Research
Learners and researchers can use AI knowledge bases to manage large amounts of information and materials. NotebookLM and Recall are particularly suitable for academic research, transforming documents into conversational knowledge sources and reinforcing memory through scientific methods. Youmind perfectly combines learning and creation, helping researchers convert learning outcomes into high-quality content output. For professionals who need to handle large amounts of information, Remio can serve as an AI second brain, automatically organizing work content. When used together with AI note-taking tools, they can form a complete personal knowledge management system.
Customer Service & Support
AI knowledge bases have extensive applications in the customer service field. Chatbase can train AI customer service agents to handle complex customer queries and provide 24/7 intelligent support. Through integration with existing systems, AI customer service can access order information, product documentation, and other key materials in real-time, ensuring accurate responses are provided. For technical support and internal consultations, Ima can provide precise answers based on enterprise knowledge bases, greatly improving service quality and efficiency.
Content Creation & Writing
Content creators and writers can leverage AI knowledge bases to spark creativity and improve efficiency. Youmind provides project-based creative spaces that seamlessly connect research, thinking, and writing. NotebookLM's audio podcast generation feature allows creators to consume and understand content in entirely new ways. AI knowledge bases can automatically organize creative materials and provide personalized inspiration suggestions to help creators break through creative bottlenecks.
Project Management & Collaboration
In project management and team collaboration, AI knowledge bases can provide powerful support. Tools like Notion and Flowith can integrate project documents, meeting notes, and team knowledge to ensure project members can access the latest information in real-time. Through AI intelligent search, team members can quickly find project-related historical decisions and solutions, improving collaboration efficiency. Intelligent workflow integration makes knowledge management more automated and intelligent. When used together with AI productivity tools, they can build a complete team collaboration ecosystem.
How to Choose AI Knowledge Base Tools
With numerous AI knowledge base tools available, how do you choose the right solution for your needs? These five key steps will help you make an informed decision.
1. Assess Knowledge Management Needs and Scale
First, clarify your knowledge management requirements: Is it for personal learning, team collaboration, or enterprise-level applications? Assess the scale of your knowledge base, number of users, and usage frequency. Individual users can choose tools like NotebookLM or Recall; small teams are better suited for Notion or Slite; large enterprises need enterprise-level solutions like Lark. Only after clarifying requirements can you select the most suitable tool.
2. Check System Integration and Data Import Capabilities
Examine the tool's data import and system integration capabilities. An excellent AI knowledge base should support importing from multiple data sources, including documents, web pages, emails, and existing systems. Check API interfaces and automated synchronization features to ensure seamless integration into existing workflows. For enterprise users, also consider compatibility with existing toolchains to avoid redundant construction and data silos.
3. Evaluate AI Capabilities and Search Accuracy
Test the core AI capabilities, including intelligent search, content comprehension, and answer generation quality. Excellent tools should be able to understand semantics, provide contextually relevant search results, and accurately answer complex questions. Consider the tool's learning capabilities and personalization features, such as Flowith and Remio which can learn user habits and provide more precise knowledge recommendations and services.
4. Review Security and Privacy Protection
Knowledge bases often contain sensitive information, making security and privacy protection crucial. Check data encryption, access controls, and compliance certifications. For enterprise users, ensure tools comply with GDPR, CCPA, and other privacy regulations. Understand data storage locations and backup mechanisms, especially for scenarios involving sensitive business information or personal data. Prioritize tools that provide local data storage and end-to-end encryption.
5. Test User Experience and Long-term Maintenance
Experience the tool's interface design, ease of use, and learning curve. An excellent AI knowledge base should be intuitive and support multi-platform access. Examine long-term maintenance capabilities, including update frequency, technical support quality, and community activity. Consider free trial periods to fully test actual tool performance, ensuring it can continuously meet knowledge management needs and adapt to future development.
Conclusion
AI knowledge base tools are reshaping how we manage and utilize knowledge, evolving from simple document storage to intelligent knowledge discovery and application. These tools not only improve individual and team work efficiency, but more importantly, change how we interact with information. Through AI-driven search, automatic summarization, and knowledge association, knowledge bases are no longer passive information repositories, but active intelligent assistants.
Choosing the right AI knowledge base tool requires considering specific usage scenarios and needs. Individual users can start experiencing the knowledge management revolution brought by AI with NotebookLM and Recall; team users can choose collaboration platforms like Notion or Slite; enterprise users should consider enterprise-level solutions like Lark. As AI technology continues to advance, we have every reason to believe that AI knowledge bases will become the mainstream approach to future knowledge management.
Whether you are a student, researcher, professional, or enterprise manager, now is the best time to start exploring AI knowledge base tools. These tools can not only help you better organize and utilize knowledge, but also inspire new ways of thinking and working methods. Let's embrace the new era of AI-driven knowledge management together!