Search Engine Basics
What are Search Engines
Search engines are searchable databases of web content, consisting of two core parts: search index (digital library storing webpage information) and search algorithms (computer programs matching results from the index). When users enter search queries, search engines use algorithms to find the most relevant results in the index and rank them by relevance. This process involves discovering pages, crawling content, building indexes, understanding queries, matching results, and ranking presentation through complex technical systems including web crawlers, indexers, retrievers, and ranking algorithms.
Search Engine Aim
Every search engine aims to provide the most relevant and useful search results. Search engines gain market share by improving result quality, and user satisfaction directly affects competitiveness and commercial value. Google holds 91% global market share because its search results are more relevant than competitors.
How Search Engines Make Money
Search engines have two result types: organic results (from search index, cannot be paid for) and paid results (from advertisers, can be paid for). Each click on paid results requires advertisers to pay search engines, known as pay-per-click (PPC) advertising. Larger market share means more users, more ad clicks, and higher revenue. Google's ad revenue accounts for over 80% of total revenue, and Bing contributes significant ad revenue to Microsoft. This business model motivates search engines to improve result quality, attract more users, and generate more ad revenue.
How Search Engines Build Index
Search engines build indexes through four steps: discovering URLs, crawling pages, processing and rendering content, and building indexes. Here's Google's simplified process:
URLs: Web Page Discovery
Everything starts with a known URL list. Google discovers new pages through: backlinks (if a known page links to a new page, Google can find it), sitemaps (site owners tell Google which pages are important), and URL submissions (site owners can request crawling of specific URLs in Google Search Console). Google has an index of hundreds of billions of pages. When someone links to a new page from a known page, Google's crawler can follow the link to discover new content. Sitemaps help site owners proactively tell search engines about site structure, speeding up discovery and indexing.
Crawling: Web Page Crawling
Web crawlers (spiders or robots) are automated programs that discover and crawl web content. Google's crawler is Googlebot, Bing's is Bingbot. Crawlers continuously discover new pages by following hyperlinks. They start from seed URLs, access initial page lists, analyze content and extract hyperlinks, adding new links to the queue. They follow rules set by site owners, mainly through robots.txt to understand which pages can be crawled. They use breadth-first (BFS) or depth-first (DFS) strategies to balance efficiency and coverage. Modern crawler systems handle crawl rate control, URL deduplication, dynamic content rendering (JavaScript), and crawl priority. Google's crawling system Trawler intelligently decides which pages need priority crawling and updating.
Processing and Rendering
Processing is where Google understands and extracts key information. Google renders pages by running page code to understand user-visible content, extracting links and storing content for indexing. Google processes various content types including HTML, CSS, JavaScript, images, and videos. For JavaScript-rendered pages, Google executes JavaScript to see complete content. This requires significant computing resources, and Google uses distributed systems to process trillions of pages.
Indexing: Building Search Library
Indexers parse raw web content crawled by crawlers into structured data, extracting keywords, metadata, and content features, and building database structures like inverted indexes for fast retrieval. Indexers parse HTML documents, extracting titles, body text, links, image alt text, and metadata. They perform natural language processing: word segmentation, stop word removal, and stemming. Finally, they build inverted indexes, mapping each keyword to all pages containing it, so search engines can quickly find relevant pages when users search.
Search indexes are what users search when using search engines. AI assistants like ChatGPT, Claude, and Gemini also use search indexes to find web pages. This is why being indexed in major search engines like Google and Bing is important. Users can't find you unless you're in the index. Modern indexing systems are massive. Google's indexing system Alexandria stores and manages index data for trillions of pages. Indexing systems handle index updates, compression, and distributed storage across multiple data centers. Index quality directly affects search result accuracy and relevance.
How Search Engines Rank Pages
Discovering, crawling, and indexing content is just the first step. Search engines need a way to rank matching results when users search. This is the job of search algorithms.
What are Search Algorithms
Search algorithms are formulas that match and rank relevant results from the index. Google uses many factors in its algorithms, which together determine which pages appear at the top of search results.
Key Ranking Factors
No one knows all Google ranking factors because Google hasn't fully disclosed them. But we know some key ones:
Backlinks
Backlinks are links from one website to another. They're one of Google's strongest ranking factors. This is why we see strong correlation between linking domains and organic traffic in studies of over a billion pages. Quality matters more than quantity. Pages with a few high-quality backlinks often outrank those with many low-quality ones. High-quality backlinks come from authoritative sites, relevant topic sites, and naturally earned links (not purchased or exchanged).
Relevance
Relevance is how useful a result is for the searcher. Google determines this in multiple ways. At the basic level, it looks for pages containing the same keywords as the search query. It also checks interaction data to see if others found the result useful. Relevance includes keyword matching, semantic relevance, topic relevance, and user intent matching. Google uses machine learning models like BERT to better understand query intent and content semantics, improving search result relevance.
Freshness
Freshness is a query-dependent ranking factor. It's stronger for searches needing fresh results. This is why you see recently published top results for "new Netflix series" but not for "how to solve a Rubik's cube." Freshness is important for time-sensitive queries like news, events, and product launches. For "how-to" queries and definition queries, content quality and authority matter more than freshness.
Page Speed
Page speed is a ranking factor on desktop and mobile. It's more of a negative factor than positive, negatively affecting the slowest pages rather than positively affecting fast ones. Page speed affects user experience. Slow-loading pages increase bounce rates and reduce dwell time. Google uses Core Web Vitals (LCP, FID, CLS) to measure page performance, which directly affects search rankings.
Mobile-Friendliness
Mobile-friendliness has been a ranking factor on mobile and desktop since Google's switch to mobile-first indexing in 2019. This means Google primarily uses the mobile version of pages for indexing and ranking. Mobile-friendliness includes responsive design, touch-friendly interfaces, fast loading speeds, and readable font sizes. Pages that don't meet mobile-friendly standards are affected in mobile search rankings.
How Search Engines Personalize Results
Google tailors search results for each user using location, language, and search history. Let's examine these factors:
Location
Google uses your location to personalize results with local intent. This is why all results for "Italian restaurant" are from or about local restaurants. Google knows you're unlikely to fly halfway around the world for lunch. For local search queries, Google prioritizes nearby businesses and services. Location information comes from user IP addresses, GPS data (mobile devices), and Google account settings.
Language
Google knows showing English results to Spanish users makes no sense. This is why it ranks localized content versions (if available) to users speaking different languages. Google determines which language results to show based on browser language settings, Google account language preferences, and search query language. For multilingual websites, Google tries to show versions matching the user's language.
Search History
Google saves what you do and places you go to provide a more personalized search experience. You can opt out, but most people probably don't. Search history affects result personalization. Google adjusts results based on past search behavior, clicked links, and visited websites. This makes each user's search results unique.
Technical SEO Considerations
Understanding how search engines work helps optimize website technical architecture and improve crawling and indexing efficiency. Technical SEO involves website structure optimization, page performance optimization, mobile-friendliness, and structured data. By optimizing robots.txt files, site owners control which pages crawlers can access. Submitting sitemaps speeds up new page discovery. Optimizing page load speed, mobile-friendliness, and structured data improves search rankings and user experience.
To learn more about technical SEO practices and optimization techniques, refer to our SEO Learning Resources page, which contains systematic SEO learning guides and best practices. You can also consult our SEO Glossary for detailed definitions and explanations of technical SEO terms like robots.txt, sitemap, structured data, and Core Web Vitals.
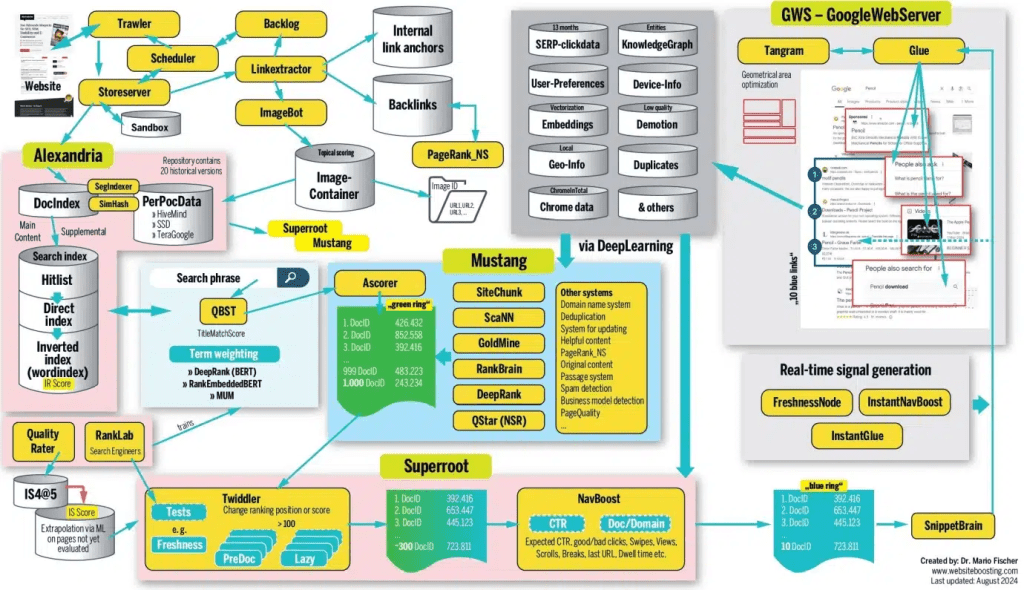
Through Google's leaked official documentation, we can see how ranking algorithms work: Google's ranking algorithm is complex, even employees participating in the algorithm cannot explain each factor's weight and how they work together; the entire system consists of many smaller systems, such as crawling system Trawler, indexing system Alexandria, ranking system Mustang, and query processing system SuperRoot.