What Are AI Model Evaluation Platforms
AI model evaluation platforms help developers, researchers, and businesses systematically test, assess, and compare AI model performance. These platforms use standardized metrics, benchmarks, and comparative analysis to determine if models meet goals, run efficiently, and suit real-world applications.
These platforms provide objective, quantifiable performance assessments for informed model selection. Whether evaluating LLM accuracy, image generation quality, or comparing API providers' speed and cost, they offer comprehensive data and insights. Systematic evaluation helps avoid unsuitable models and optimize AI application performance and costs.
How AI Model Evaluation Platforms Work
AI model evaluation technology centers on metric design, benchmark construction, performance comparison, and result visualization. Platforms design metrics covering accuracy, speed, cost, and safety across AI tasks (NLP, computer vision, multimodal). Benchmarks involve standardized datasets, test scenarios, and evaluation criteria for objective, reproducible results.
Performance comparison requires collecting data from many models through automated testing and real-time monitoring. Visualization uses leaderboards, comparison charts, and detailed reports. As AI evolves, platforms integrate advanced methods like LLM-as-a-Judge, multi-dimensional frameworks, and real-time monitoring for comprehensive evaluation support.
Best AI Model Evaluation Platforms 2026
Leading AI model evaluation platforms offer comprehensive testing, benchmarking, and performance analytics. These platforms provide developers, researchers, and enterprises with objective metrics to compare models, optimize performance, and ensure reliable AI applications.
1. Artificial Analysis: AI Model & API Provider Analysis
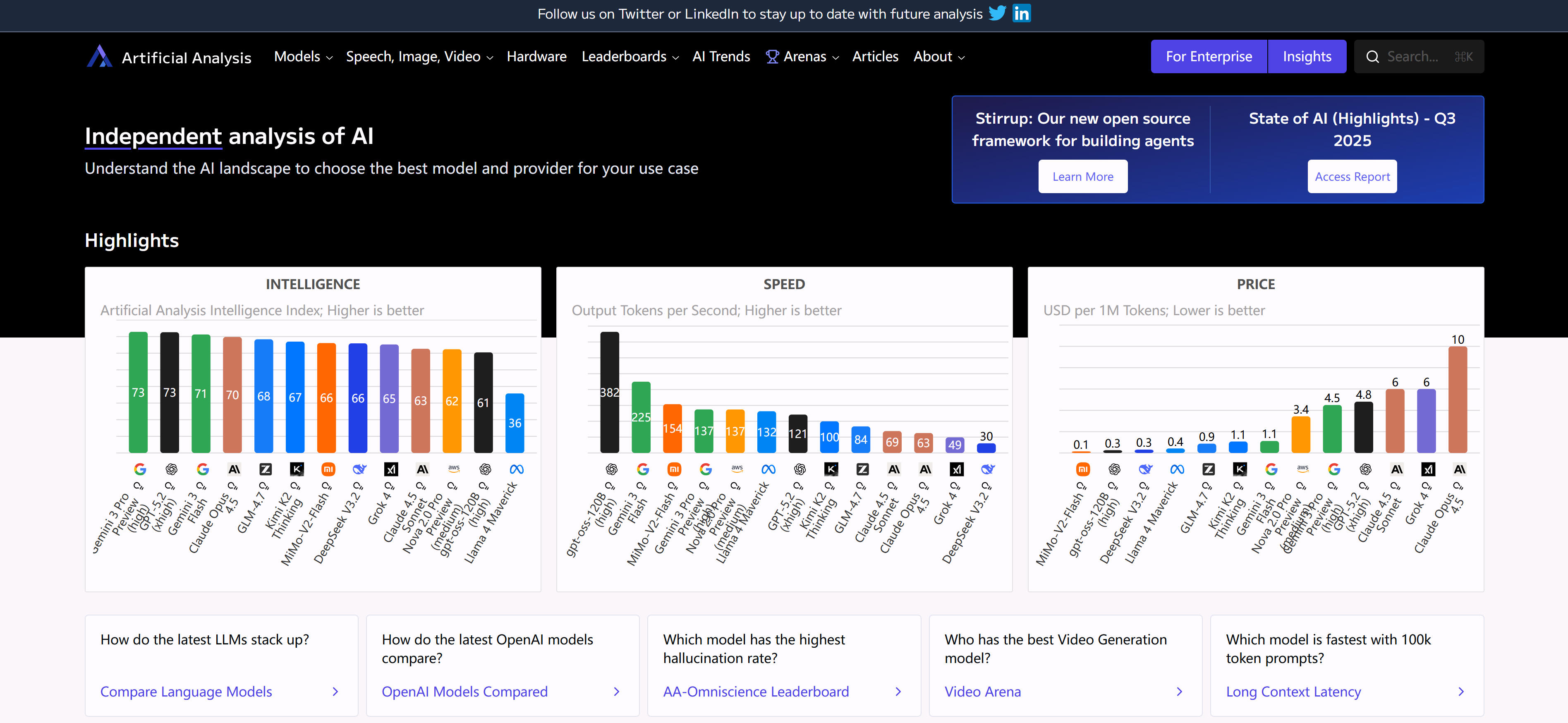
Artificial Analysis is a professional platform analyzing AI models and API providers, evaluating performance, speed, cost-effectiveness, and reliability. Through systematic benchmarks and real-time monitoring, it provides comprehensive comparison data to help users choose optimal AI services. Features include comprehensive API provider coverage, detailed performance metrics, cost comparisons, and reliability assessments. The platform offers intuitive comparison charts and detailed reports for quick insights into provider strengths and weaknesses. For developers and businesses selecting AI API services, Artificial Analysis provides essential decision support.
2. LMArena: AI Model Comparison Platform
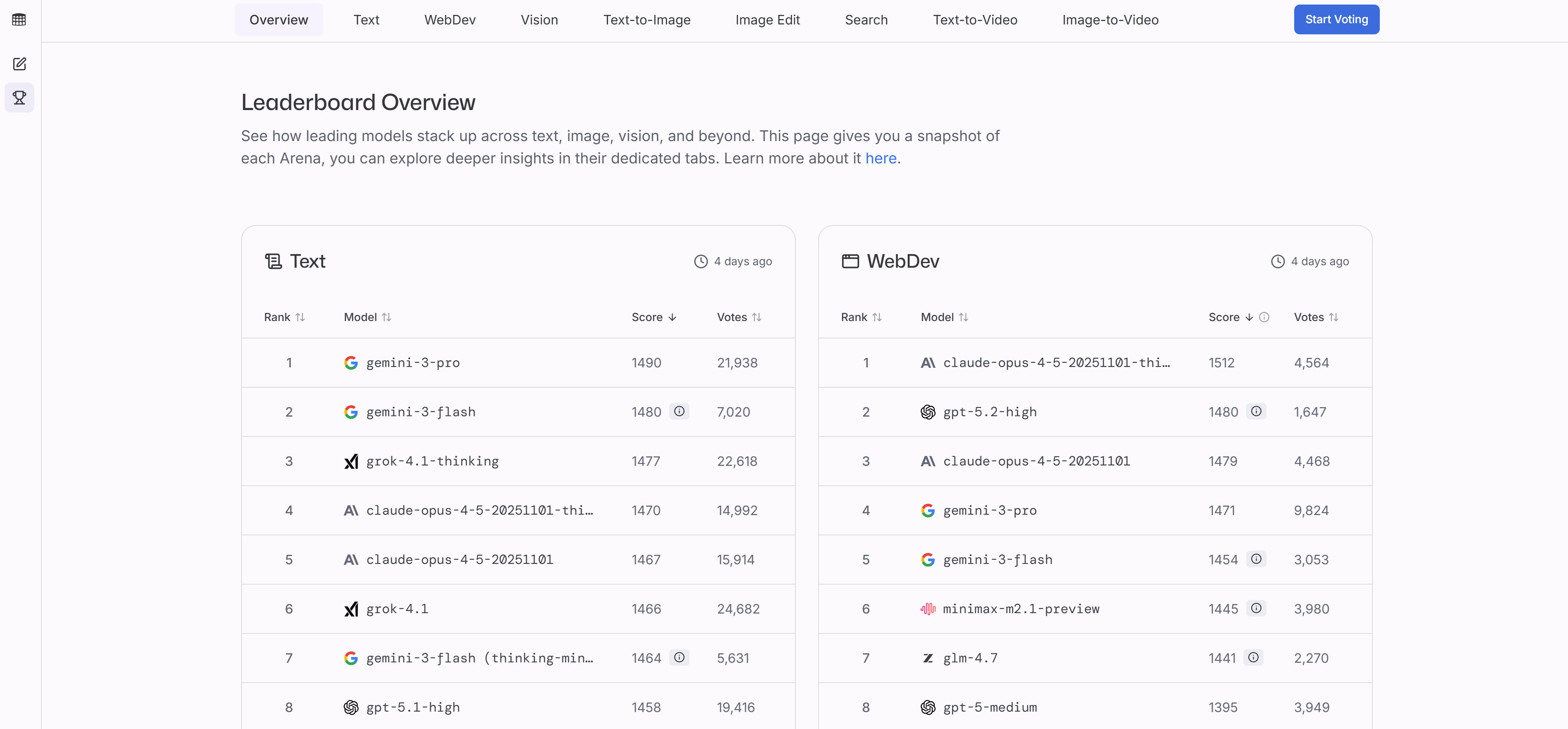
LMArena is an innovative platform for side-by-side comparison and evaluation of AI models' performance, accuracy, speed, and suitability. It focuses on analyzing model performance rather than creating AI, helping users find models best suited for specific tasks through systematic testing and comparison. Features include intuitive comparison interface, multi-dimensional performance assessment, real-time testing, and community feedback. Users can input test cases to compare response quality and performance. Public leaderboards and community feedback provide latest performance and user reviews. For developers and businesses selecting AI models, LMArena offers convenient comparison tools.
3. Scale SEAL: Expert-Driven LLM Leaderboard
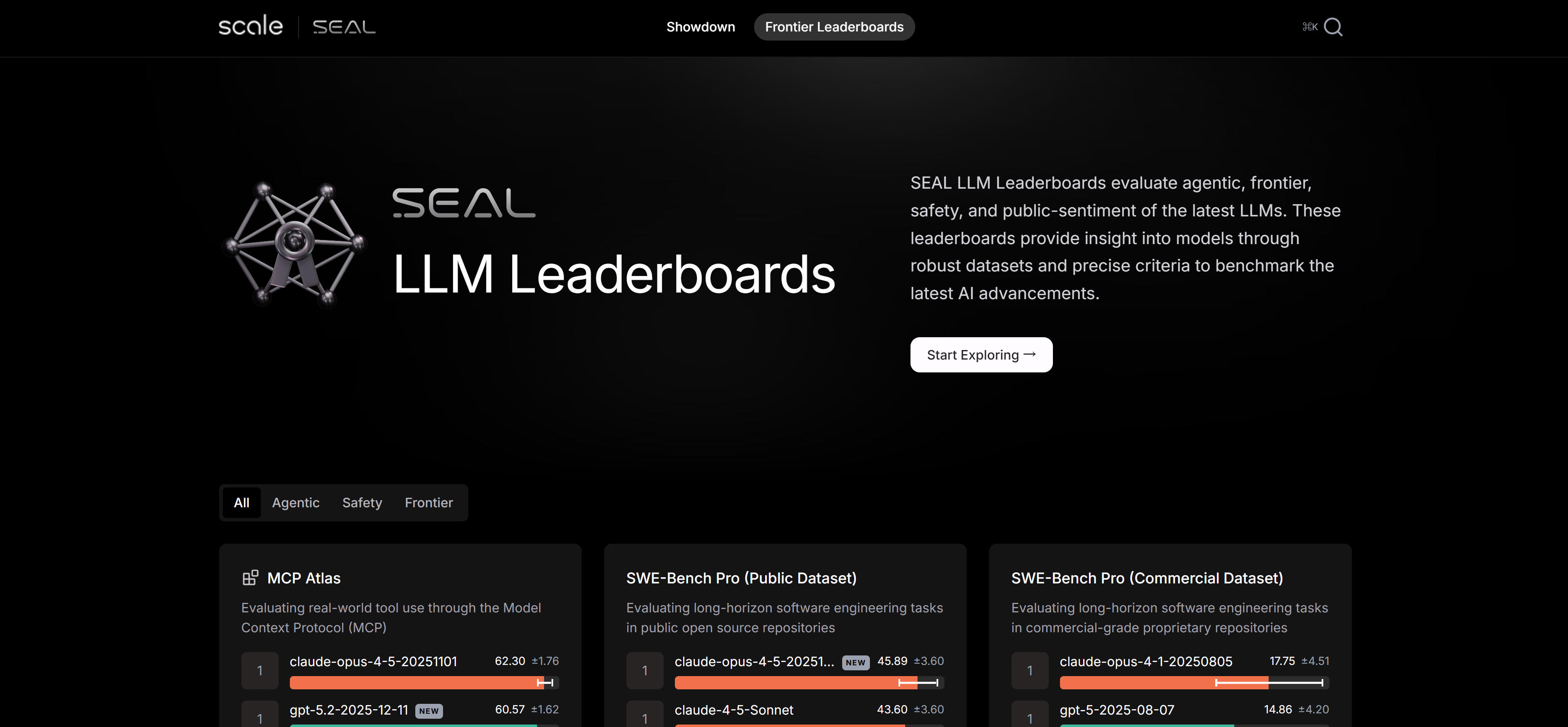
Scale SEAL (Systematic Evaluation of AI Language Models) is Scale's expert-driven LLM evaluation leaderboard using rigorous standards and professional methods for systematic performance assessment. It focuses on frontier AI capabilities, providing authoritative model performance rankings for researchers and developers. Features include expert-driven evaluation methods, rigorous standards, comprehensive capability testing, and continuously updated leaderboards. The platform evaluates model performance across tasks including reasoning, knowledge understanding, and code generation. Results undergo professional review for objectivity and accuracy. For researchers and developers tracking frontier AI model performance, Scale SEAL provides authoritative evaluation reference.
4. OpenRouter Rankings: LLM Usage Leaderboard
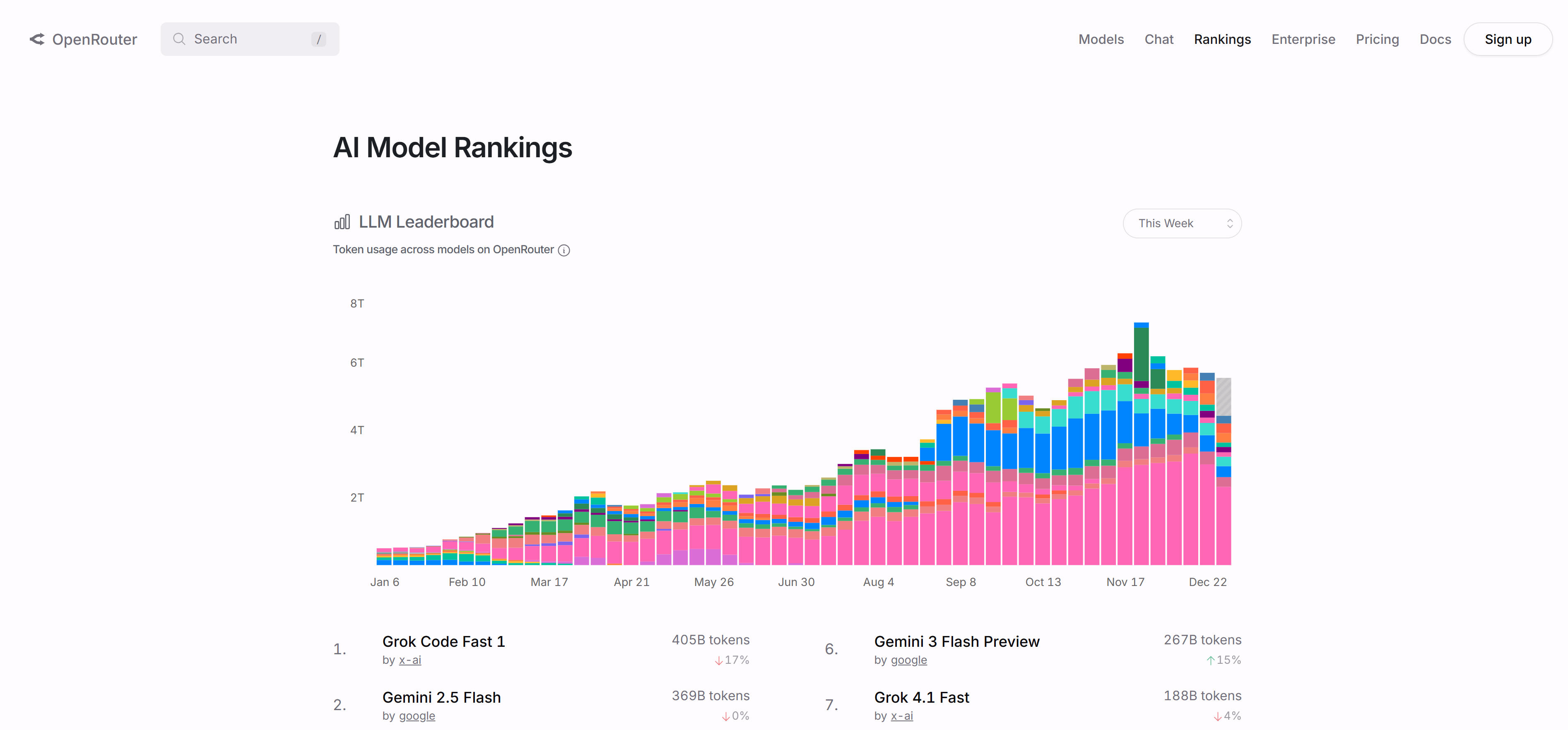
OpenRouter Rankings is an LLM leaderboard based on real usage data, tracking actual model usage on OpenRouter to provide market-driven rankings. It shows model usage share and performance across code generation, conversation, multilingual, and other scenarios. Features include rankings based on real usage data, multi-dimensional scenario analysis, market share statistics, and real-time updates. The platform provides model comparisons by use case, language, programming language, context length, and more, helping users understand real-world performance. For developers and businesses understanding market acceptance, OpenRouter Rankings offers unique market perspective.
5. Galileo AI: AI Observability & Evaluation Platform
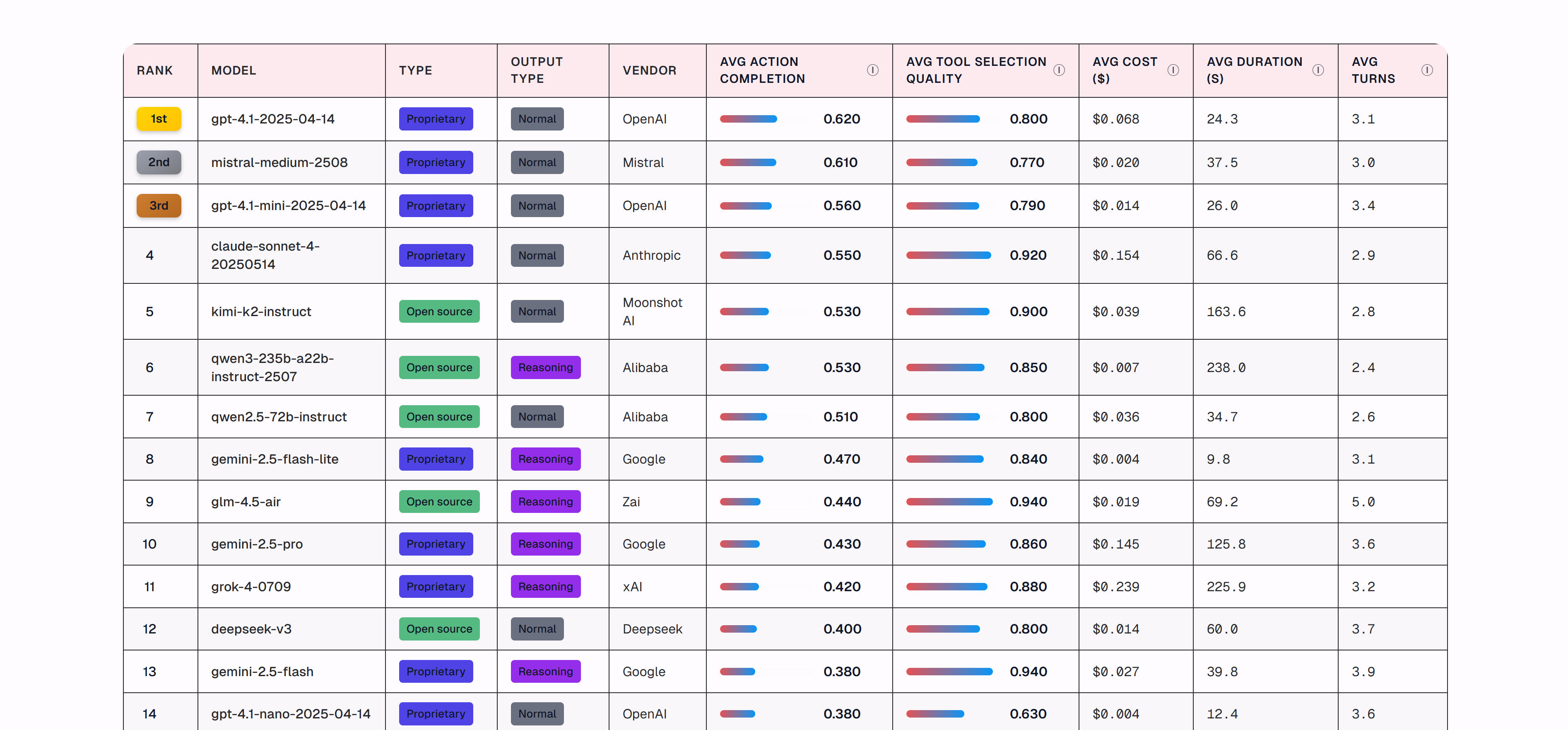
Galileo AI is a professional AI observability and evaluation engineering platform focusing on offline evaluation and production monitoring. It provides complete lifecycle management from evaluation to guardrails, helping developers build reliable, secure AI applications. Features include comprehensive evaluation metrics library, auto-tuned evaluation methods, eval-to-guardrail conversion, real-time monitoring and alerts. The platform supports RAG evaluation, agent evaluation, safety and security assessments, and provides Luna models converting expensive LLM evaluations into low-cost, low-latency monitoring models. For enterprises building production-grade AI applications, Galileo AI offers complete evaluation and monitoring solutions.
6. Evidently AI: AI Evaluation & LLM Observability Platform
Evidently AI is an open-source AI evaluation and LLM observability platform offering 100+ built-in metrics, supporting LLM testing, RAG evaluation, adversarial testing, AI agent testing, and more. Built on the open-source Evidently Python library, it provides transparent, extensible evaluation tools. Features include rich metrics library, open-source transparency, easy extensibility, custom evaluation support, and continuous testing. The platform provides automated evaluation, synthetic data generation, continuous monitoring to help developers quickly identify model issues, data drift, and performance regressions. It supports RAG evaluation, adversarial testing, agent workflow validation, and more, offering comprehensive quality assurance for AI application development. For developers needing open-source evaluation tools, Evidently AI provides powerful evaluation and monitoring capabilities.
AI Model Evaluation Platform Comparison
Compare the leading AI model evaluation platforms to find the best solution for your needs:
Use Cases: AI Model Evaluation Applications
AI model evaluation platforms play important roles in different scenarios, providing decision support for model selection and performance optimization for developers, researchers, and businesses.
Model Selection and Comparison
Use LMArena and Artificial Analysis to compare AI model performance, accuracy, and speed, selecting models best suited for specific tasks. Understand model performance in authoritative evaluations and real usage through Scale SEAL and OpenRouter Rankings for informed decisions. Leverage comparison analysis to consider performance, cost, reliability, and other factors for optimal AI service provider selection.
Model Development and Optimization
Use Galileo AI and Evidently AI for model evaluation and testing, identifying performance issues and improvement directions. Track model performance changes through continuous monitoring and evaluation, detecting data drift and regressions early. Leverage evaluation data to guide model optimization and iteration, improving AI application reliability and performance.
Production Monitoring
Use Galileo AI and Evidently AI to monitor AI systems in production, ensuring stable operation. Detect AI system anomalies and performance issues through real-time evaluation and alerts. Leverage guardrail features to automatically block harmful responses and anomalies, ensuring AI application security.
Research and Academic Evaluation
Use authoritative platforms like Scale SEAL to understand latest performance of frontier AI models. Conduct model research and performance comparison using standardized evaluation methods. Leverage evaluation data to support academic research and publications, advancing AI technology.
How to Choose AI Model Evaluation Platforms
Choose the right tool based on your specific needs, quality requirements, budget, and ease of use.
1. Evaluate Your Needs
Define evaluation purpose: Determine if your main need is model comparison, performance assessment, production monitoring, or research analysis. For model comparison, LMArena and Artificial Analysis are more suitable; for production monitoring, Galileo AI and Evidently AI are better; for authoritative evaluation, Scale SEAL is preferred.
2. Assess Output Quality
Assess metrics and features: Check if platforms provide needed evaluation metrics and features. Different platforms support different evaluation types, metric ranges, and testing capabilities. For example, Galileo AI and Evidently AI offer more comprehensive metric libraries, while LMArena and Artificial Analysis focus more on model comparison.
3. Consider Budget and Pricing
Consider technical integration: Evaluate platform integration capabilities and API support. For enterprises needing integration into existing systems, platforms with APIs and SDKs are more suitable. Galileo AI and Evidently AI offer better integration capabilities, while comparison platforms mainly provide web interfaces.
4. Evaluate Usability
Evaluate cost and budget: Consider platform usage costs and pricing models. Open-source platforms (like Evidently AI) are usually free but require self-deployment and maintenance; SaaS platforms (like Galileo AI) provide hosted services but require payment; comparison platforms are typically free but may have limited features.
5. Check Feature Completeness
Check data security and compliance: For enterprise users, check platform data security measures and compliance certifications. Ensure platforms meet data protection requirements, support private deployment, or comply with enterprise security standards. Galileo AI and Evidently AI provide enterprise-grade security and compliance support.
Conclusion
AI model evaluation platforms provide essential evaluation and decision support tools for AI application development, from model selection to performance optimization, from development testing to production monitoring. Comparison platforms (like LMArena, Artificial Analysis) help users quickly compare and select models; authoritative evaluation platforms (like Scale SEAL) provide professional model performance rankings; usage data platforms (like OpenRouter Rankings) show real-world application performance; evaluation engineering platforms (like Galileo AI, Evidently AI) offer comprehensive evaluation and monitoring capabilities.
Choosing suitable platforms requires comprehensive consideration based on specific needs, use cases, and technical capabilities. For users needing quick model comparison, LMArena and Artificial Analysis provide convenient comparison tools; for enterprises needing production monitoring, Galileo AI and Evidently AI offer complete evaluation and monitoring solutions; for researchers focusing on authoritative evaluation, Scale SEAL provides professional evaluation reference. Whatever your needs, you can find suitable evaluation tools and support in these platforms.